Spreadsheet driven development

Andrei Zhozhin
| 13 minutes

Big and complex systems are not created big and complex they are growing organically over years and are written by “generations” of developers. At some point, accidental complexity could breach a particular threshold and new changes (even trivial ones) could be very hard to implement without breaking something else. I’d like to share an approach that could help to extract some pieces of the code into the dedicated location (read configuration) and make it maintainable. Imagine that you have a class hierarchy where classes on top of the hierarchy are more abstract and leaf classes are very concrete. Also, every class has its own rules on how to identify if a sample is matching this “node” or not (read it has IsApplicable() method). The process takes a sample object and checking all classes in the hierarchy from the top and trying to find an applicable one. Let’s call this classification process. Classes on top of the hierarchy have a “common prefix” for their children - a set of attributes and the values that should match before you dive deeper. There is also some kind of fallback class on every level of hierarchy that would be assigned to the sample if other nodes on that level are not applicable.
Example with geometric shapes hierarchy:
 Imagine that every leaf node could calculate the area of the shape based on the rotation (identified using check-in corners) and boundaries (width and height or rectangular area). Fallback options
Imagine that every leaf node could calculate the area of the shape based on the rotation (identified using check-in corners) and boundaries (width and height or rectangular area). Fallback options TriangularFallback and SquareFallback (highlighted as orange) provide a slow computation model as we need to calculate rotation angle first and then calculate area. ShapeFallback would calculate area approximately based on colour analysis in pixels. So if we have a simple class (Triangle, Square, or rotated variants) we can calculate area quickly and precisely, if we have one of the fallback options for triangles and squares - we calculate slower and with high accuracy, and if we fail to identify shape - we calculate using slowest method (we need to count all pixels) and not very accurate.
Now let’s switch to something more interesting - financial instruments. Their classification could be more diverse (especially exotic derivatives)
Real financial instruments (from Wikipedia):

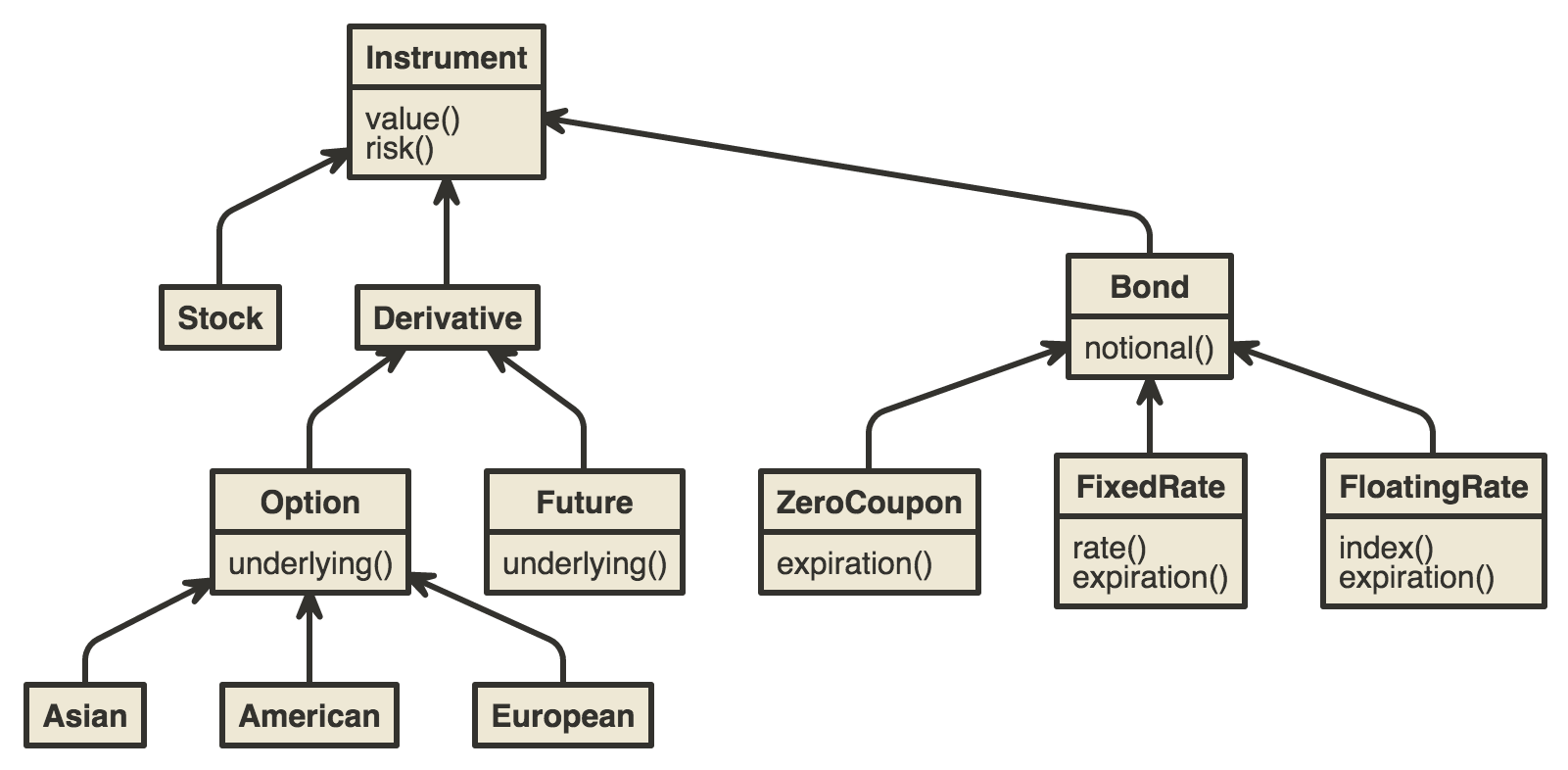
I’ve googled for financial instrument hierarchy, found one, and I composed my version.
Here is a class hierarchy of instruments I’ll be using in example (real hierarchy is much bigger):
 Please note, there is no fallback for the
Please note, there is no fallback for the Derivative level, as it is either Option or Future, so the Future kind of fallback.
Please note, I would not implement everything properly, like proper error and corner case handling (as I don’t have much time), but it would include all necessary logic to make it work.
Let’s assume that we already have all logic implemented in the classes so we have a full hierarchy. Once such a hierarchy reaches some size, for example, 50+, it would be very hard to make changes to it, so we need to make sure that new rules do not interfere with old ones. I would try to explain how I would approach this problem and propose implementation.
Our goal would be to make classification logic clear, understandable, and maintainable for large hierarchies.
First steps
As the initial step, we need to compose a table with all rules that we currently had in the system with their types.
Convention: value 'X' in the cell for particular column PropA means that PropA == 'X'
Simple cases like the following (all non-empty cells are joined together to produce Target Type/Instrument)
| PropA | PropB | PropC | Target Type |
|---|---|---|---|
| ‘X1’ | ‘Y1’ | Instrument A | |
| ‘X2’ | ‘Z1’ | Instrument B | |
| .. | .. | .. | .. |
| ‘Yn’ | Instrument N |
As we go further the instruments table would expand (more columns needs to be added), and complexity starts to grow (not only simple values start to appear in the cells, but arrays of values (IN clause), and negated arrays of values (NOT IN clause)). Also, rules in hierarchy kind of adding “common prefix” (set of columns with particular value) for all children classes.
| PropA | PropB | PropC | PropD.ElementD1 | PropE.ElementE1.SubElSE1 | Target Type |
|---|---|---|---|---|---|
| .. | .. | .. | .. | .. | .. |
| [‘X1’, ‘X2’] | [‘Y1’, ‘Y2’] | ‘Z1’ | Instrument X | ||
| [‘X1’, ‘X2’] | not [‘Y1’, ‘Y2’] | ‘Z1’ | Instrument Y | ||
| ‘Z1’ | [‘K1’, ‘K2’, ‘K3’] | Instrument Z |
Another level of complexity is related to fallback logic, which means if a sample was matching a higher level of hierarchy but was not matching all the “children” it should be assigned to a particular fallback class. There was a problem adding these rows to the table as at this point every row was identifying Target Type precisely, and adding a fallback option for every known “common prefix” was not possible with the current table structure. And that means that the trivial table model does not work, and it should be amended to support fallbacks.
The idea came from the model of firewall rules when every rule has its number, and packet “travels” through the table of rules (last rule in the table is to deny packet) top-to-bottom until it would first match particular rule and this rule (accept or deny) would be applied to it. It was exactly the behaviour we need if something does not apply there is the next rule with the same “common prefix” that would assign a fallback type.
Firewall-like table for classification
This new model (with fallbacks) requires introducing order for all rules, and we need to sort our table somehow. The criteria were the following:
- if a rule is very specific (it has many rules/non-empty cells) it should be higher in the table
- if a rule is less specific/more abstract it is lower in the table
Rules related to the same entity should be grouped, so it would be easier to understand them. This approach also supports the idea of fallbacks. If you have specific rows defining “child” classes (of class hierarchy) and all of them did not match they should be followed by a row with “common prefix” (set of common table columns) with a target fallback option.
At the bottom of the table, there should be a global fallback type, or it should throw an exception as we were not able to identify an example based on our classification rules.
Having such a table created for existing code dramatically simplify adding new classes to support new instruments, as you can see where in the table you need to add new rows and what fallback options would apply to it.
Sample firewall table with IPFW (first you have an action: allow or deny, and then set of properties of a packet to check: tcp/udp/icmp, from x, to y, fragmentation flag, via an interface, etc)
010 allow all from any to any via lo0
020 deny all from any to 127.0.0.0/8
030 deny all from 127.0.0.0/8 to any
040 deny tcp from any to any frag
050 check-state
060 allow tcp from any to any established
070 allow all from any to any out keep-state
080 allow icmp from any to any
110 allow tcp from any to any 21 in
130 allow tcp from any to any 22 in
170 allow udp from any to any 53 in
175 allow tcp from any to any 53 in
200 allow tcp from any to any 80 in
500 deny log all from any to any
Modeling table
Having a table with all rules is great, but we also have now a lot of classes describing different instruments, how to keep the table and the code in sync? The solution is to extract this classification logic from classes to “table” and perform classification differently. Rather than trying to traverse class hierarchy and check if class IsApplicable() we need to traverse our new “table” and check if the particular row is “matching”. Once we’ve found a matching row we are done with classification.
You can think about the decision tree here, for sure this table could be represented as a decision tree but the number of nodes of such tree would be too big to be able to understand it (for big hierarchies). One of the goals was to preserve readability for a non-developer person.
Remember that values in the cell is not trivial value but more complex thing, there are multiple options here:
- single value (number or string), if value presents it means
PropX = value - array of values (numbers or strings), if value presents it means
PropX in (v1, v2, ...) - “not array” of values (numbers or strings), if value presents it means
PropX not in (v1, v2, ...) - null and non-null vales
PropX is nullorPropX is not null
If the value is absent in the cell, then it (column/property) would not participate in the comparison.
Our table has about 10 columns with different properties(or property accessors). So we would need to model this somehow in the code. There are two options:
- code generation
- use of expression language
I’ll show an approach with expression language (code generation would work faster, but it would be harder to implement), fortunately, we had Spring and SpringEL.
So the plan would be the following:
- generate a table with expressions for every row on the startup
- for every non-empty cell in the column: construct a sub-expression for this property
- join all sub-expressions into the final expression
- pre-compile expressions to be evaluated with multiple trades
- traverse table with example trade to find first matching rule and use target type to create instrument class
- if the last rule is executed - either use global fallback or throw an exception
AND and OR semantics
As all columns by default are added to the final expression with AND clause (PropA == ‘X’ AND PropB == ‘Y’) there might be a question: “how to add rules with OR clause?”
Let’s look at the following example:
There is an object with 3 properties: A, B, C
And there are 3 target classes we want to identify with the following rules:
| Rule | Target Class |
|---|---|
A='X' AND B='Y' AND C='Z' |
FirstClass |
(A='X' OR B='Y') AND C='Z' |
SecondClass |
A='X' OR B='Y' OR C='Z' |
ThirdClass |
The idea is to break expression with OR clauses into several expressions with only AND clause, while Target Class should be the same.
(A='X' OR B='Y') AND C='Z' -> SecondClass could be represented by 2 following rules:
A='X' AND C='Z' -> SecondClassB='Y' AND C='Z' -> SecondClass
The following expression A='X' OR B='Y' OR C='Z' -> ThirdClass could be represented by 3 following rules:
A='X' -> ThirdClassB='Y' -> ThirdClassC='Z' -> ThirdClass
So our final table would have not 3 but 6 rows:
| A | B | C | Target Class |
|---|---|---|---|
| ‘X’ | ‘Y’ | ‘Z’ | FirstClass |
| ‘X’ | ‘Z’ | SecondClass | |
| ‘Y’ | ‘Z’ | SecondClass | |
| ‘X’ | ThirdClass | ||
| ‘Y’ | ThirdClass | ||
| ‘Z’ | ThirdClass |
Rule mapping
Spring Expression Language does not provide the syntax we want, thus we need to model our syntax in the table (readable by business users) to syntax available to developers in SpEL.
Our prop column value |
SpEL equivalent |
|---|---|
1 |
prop == 1 |
not 1 |
prop != 1 |
'str' |
prop == 'str' |
not 'str' |
prop != 'str' |
null |
prop eq null |
not null |
prop ne null |
[1, 2] |
{1, 2}.contains(prop) |
not [1, 2] |
!{1, 2}.contains(prop) |
['A', 'B'] |
{'A', 'B'}.contains(prop) |
not ['A', 'B'] |
!{'A', 'B'}.contains(prop) |
Show me the code
An example of how to use Spring Expression Language
The object that we would use in an expression context
// Class with a single String property
public class Trade {
private String type;
public Trade(String type) {
this.type = type;
}
public String getType() {
return type;
}
}
Creation of parser, context, and getting the value
// Object to operate on
var trade = new Trade("Bond");
// Prepare our expression
var parser = new SpelExpressionParser();
// Notice that String value('Bond') is enclosed in single quotes
var expression = parser.parseExpression("type == 'Bond'");
// We can omit context here as we don't use any extra variables
var context = new StandardEvaluationContext(trade);
// getting result of expression, it should return boolean value
var result = expression.getValue(context, Boolean.class); // would be true
Now let’s define several methods in the ExpressionFactory factory class to implement conversion
public class StringExpressionFactory {
...
public String equalTo(String accessor, Object value) {
var stringValue = escapeSingleValue(value);
return "%s == %s".formatted(accessor, stringValue);
}
public String notEqualTo(String accessor, Object value) {
var stringValue = escapeSingleValue(value);
return "%s != %s".formatted(accessor, stringValue);
}
public String isNull(String accessor) {
return "%s eq null".formatted(accessor);
}
public String isNotNull(String accessor) {
return "%s ne null".formatted(accessor);
}
public String inStringList(String accessor, List<String> list) {
var escapedValueListStr = String.join(", ", escapeValueList(list));
return "{%s}.contains(%s)".formatted(escapedValueListStr, accessor);
}
public String inNumericList(String accessor, List<String> list) {
var escapedValueListStr = String.join(", ", list);
return "{%s}.contains(%s)".formatted(escapedValueListStr, accessor);
}
public String notInStringList(String accessor, List<String> list) {
var escapedValueListStr = String.join(", ", escapeValueList(list));
return "!{%s}.contains(%s)".formatted(escapedValueListStr, accessor);
}
public String notInNumericList(String accessor, List<String> list) {
var escapedValueListStr = String.join(", ", list);
return "!{%s}.contains(%s)".formatted(escapedValueListStr, accessor);
}
}
The only thing remaining is to parse Spreadsheet/CSV and convert human-readable expressions into our expressions.
Main logic to parse spreadsheet to expression table. You can check the full source code of SpreadsheetParser in git repository.
Notice, that for string list we are escaping values
public class SpreadsheetParser {
public LinkedHashMap<Expression, String> parse() {
...
for (var row : rowsList) {
var rowResult = parseRow(row);
var exps = convertPartsToExpressionList(factory, rowResult.parts);
String fullExpression = String.join(" and ", exps);
// if we have nothing as final expression it should be last effective row (true)
var expression = !fullExpression.equals("")
? expressionParser.parseExpression(fullExpression)
: expressionParser.parseExpression("true");
expressionTable.put(expression, rowResult.target);
}
...
}
private RowResult parseRow(Map<String, String> row) {
...
for (Map.Entry<String, String> entry : row.entrySet()) {
if (entry.getKey().equals(this.targetColumn)) {
target = entry.getValue();
} else {
var value = entry.getValue();
// empty cells are not added to result
if (value != null && !value.equals("")) {
var cell = this.valueParser.covertInputString(value);
parts.put(entry.getKey(), cell);
}
}
}
...
return new RowResult(target, parts);
}
private List<String> convertPartsToExpressionList(
StringExpressionFactory factory, Map<String, MyObject> parts) {
var exps = new ArrayList<String>();
for (var part : parts.entrySet()) {
var accessor = part.getKey(); // property accessor expression/column name
var myObj = part.getValue();
if (myObj instanceof MyNull) {
exps.add(myObj.isNegate()
? factory.isNotNull(accessor)
: factory.isNull(accessor));
} else if (myObj instanceof MyNumber) {
...
...
} else {
throw new SpreadsheetParseException(
"Unknown object type detected: %s".formatted(myObj.getClass()));
}
}
return exps;
}
}
Final result
So, now we have a spreadsheet with defined rules, some code that can transform this table into a set of rows for classification table using SpEl, and some code that tests that rules work correctly.
At this point, the one literarily can program using spreadsheet adding new columns (property accessors) and cell values (values to check property versus) if required and create new rules by adding new rows.
Final rule table to classify trades based on their attributes (for example instrument hierarchy)
 In orange, there are two fallbacks (FallbackBond and FallbackOption), in yellow - global fallback (no expressions are defined) so it would match if all previous rules have failed.
In orange, there are two fallbacks (FallbackBond and FallbackOption), in yellow - global fallback (no expressions are defined) so it would match if all previous rules have failed.
Summary
This is a very specific case where such an approach works, should you have more complicated logic the rule table might become too big and too complicated to understand. After we’ve extracted all classification logic into the table it is very easy to understand how everything works. Also, the table works as a source of truth so we have all logic in one place - in the table.
Links
- https://github.com/azhozhin/spreadsheet-driven-development
- https://en.wikipedia.org/wiki/Financial_instrument
- https://en.wikipedia.org/wiki/Option_(finance)
- https://en.wikipedia.org/wiki/Futures_contract
- https://docs.spring.io/spring-framework/docs/3.2.x/spring-framework-reference/html/expressions.html


{kind=link}